“Intelligence is the ability to adapt to change.” – Stephen Hawking
How did David emerge victorious in the battle with Goliath? With a slingshot. From the five stones he had picked up for the battle, David just needed one stone to defeat the giant (Book of Samuel, Old Testament). While much has been written about his intelligence and valor, his aim streamlined and precise was just as important in ensuring Goliath’s defeat. From a purely technical standpoint, since we are in the technology and data business, had David been late by a split second, or had his aim not been streamlined or precise, the story of David and Goliath would have had a different ending.
Similarly, in financial and capital markets, there is a lot that can be achieved (or lost) when processes are not streamlined, particularly in critical areas like invoice processing. Just as David’s perfectly timed and streamlined shot delivered maximum impact, a streamlined invoice processing mechanism shields organizations from irritants such as delays, errors, and penalties, and future proofs them from disruptions and missed opportunities.
Understanding the Essence of Invoice Processing
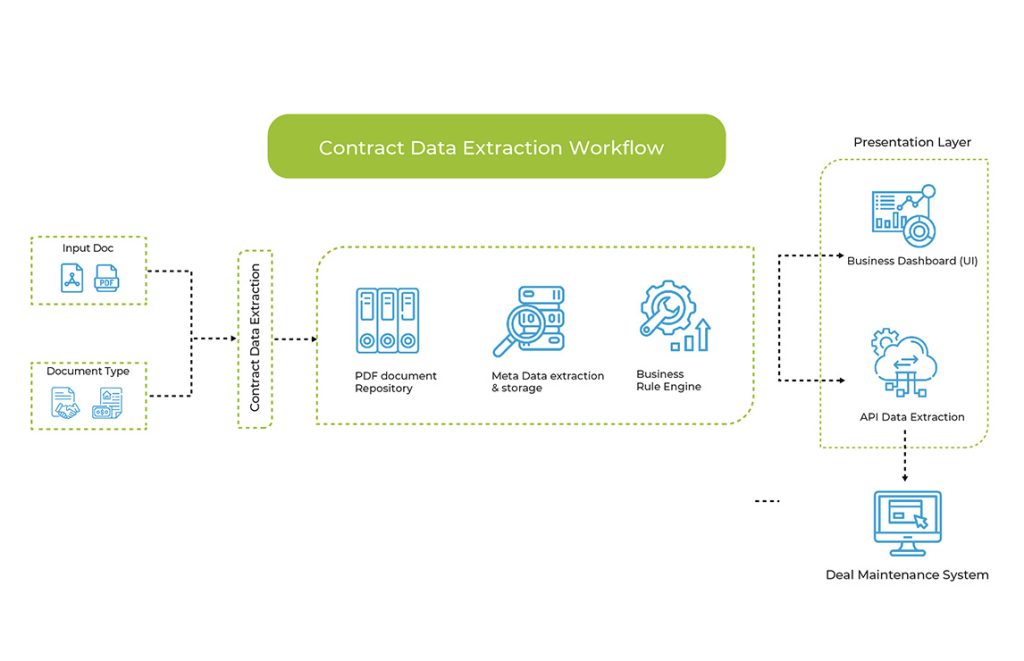
In simplest terms, invoice processing is defined as the series of steps that takes place right from the time when the supplier invoice is received to the time when it is paid and recorded in the general ledger. The invoice can be received via mail, or as a PDF attached to an email, or as an e-invoice. Whatever the format, the invoice must be manually/automatically scanned into the accounting system, digitized, ETL performed, data validated, and later inserted in the workflow approval and payment system.
Why Manual Invoice Processing is No Longer Viable
While earlier, invoice processing was largely dependent on human effort, most organizations are now moving to some forms of invoice automation solutions. This shift is primarily driven by the complexities of global financial and capital markets, which involve multiple asset classes. Manually processing invoices is impractical due to the higher likelihood of errors introduced by humans and the significant amount of time it takes, such as a lengthy 19-day process. Consequently, implementing automated workflows with Straight-Through Processing (STP) becomes a strategic investment that empowers firms to improve their spending practices and enhance efficiency.
Getting there: Why Rules-Based AI/ML Engine Critical for End-to-End Automation
While hedge funds and asset managers invest in intelligent platforms like Coupa and SAP Concur, they are still unable to accrue the true benefits. Many still rely on manual labor at some stages of invoice processing. For example, while an automated platform makes the processes of extraction of relevant information easy from the plethora of document types, there are other more complicated information that must be extracted for non-PO invoices, such as allocation and tax withholding, which require a more advanced invoice processing solution than just plain data extraction or OCR. It requires the application of pertinent business rules for ensuring that invoices are processed correctly and do not result in compliance or regulatory failures. While a centralized invoice receipt, digitized information (including data from emails, faxes, and email attachments) and optimized processes – internal sources and outsourced integrations) are prerequisite for ensuring productivity and efficiency, but for true transformation, additional value with quality and compliance, absolute traceability, and control end-to- end is also necessary. And hence the need for a platform like Magic DeepSightTM for both structured and unstructured invoices.
Magic DeepSightTM : When your need is for a Streamlined and Advanced Solution
Since we are talking about the David and Goliath, all it takes to sort out the invoice processing problems is well-sorted, streamlined solution like DeepSightTM, that can be easily integrated with existing invoice processing platforms and organization-wide workflows, organizations can counter traditional invoice processing woes related to lack of efficiency, high costs, no real-time financial visibility, non-compliance, penalties, reputation damage, business disruptions, and revenue leakage with ease.
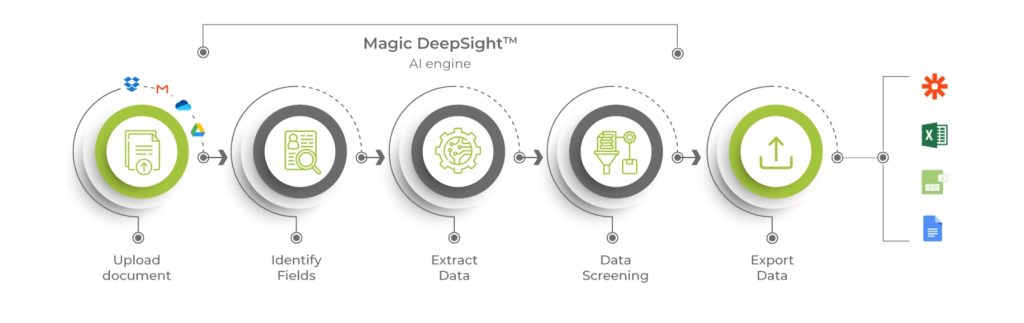
DeepSightTM brings together the best-of-breed technologies such as AI, Robotic Process Automation (RPA), machine learning, a rules-based engine, and analytics, to integrate seamlessly in existing systems and transform how your businesses handle invoice data. Highly advanced, DeepSightTM builds up the right momentum for modern enterprises (enriches data quality with a rules-based, deep learning/self-learning approach), and facilitates institutions to make well-informed decisions. Its user-friendly interface is a significant value-add as it helps finance teams be aligned and on the same page.
What makes DeepSight an Exceptional Tool for Automated Invoice Processing
- Complete End-to-End Solution
DeepSight is the ideal solution if you seek an end-to-end approach. It ensures a smooth and efficient invoice processing experience, whether you’re dealing with PO or non-PO invoices, requiring minimal human intervention. While conventional automated Invoice Processing platforms, even the most intelligent ones, focus on data classification, extraction, and cleansing, they fail to utilize business rules for determining the appropriate invoice allocation for non-PO invoices, necessitating manual work. However, DeepSight stands apart with its intelligent data technology. Its AI/ML engine not only extracts data but also offers significant value by performing critical analytical functions. This capability proves invaluable for Hedge Funds, Investment Managers, and Brokerages handling a vast number of non-PO invoices alongside their PO invoices.
DeepSight utilizes a pre-built, highly intelligent, advanced, and comprehensive rule-based AI/ML engine to effortlessly determine allocations and tax withholding. This process effectively meets essential compliance and stakeholder requirements while preventing revenue losses. The enhanced invoice information, also referred to as the golden data, is securely stored in the internal accounting system through Magic FinServ’s API for accurate record keeping. By offering a single window or centralized single source of truth, it promotes transparency and traceability.
DeepSight’s continuous upgrades and updates enable it to adapt to new information using its pre- trained AI/ML and rule-based data extraction capabilities. This results in an end-to-end automated solution that learns with minimal supervision, making it an exemplary version of such a comprehensive solution. - Rules-Based Data Extraction through Pre-Trained AI/ML Models
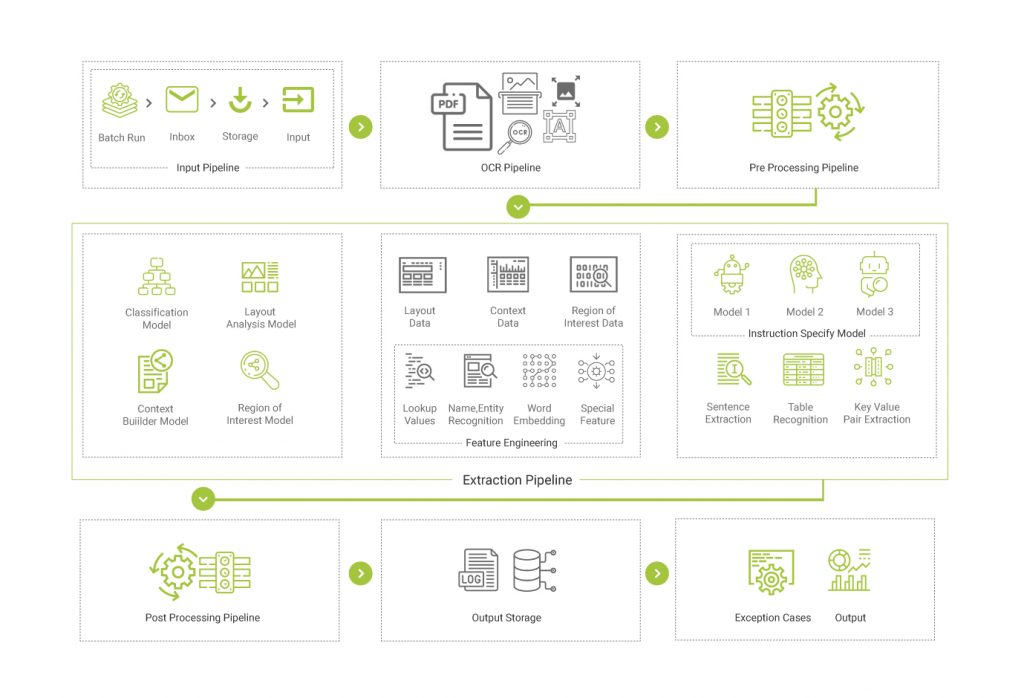
DeepSight’s intelligent document content recognition performs accurate identification, classification and segregation of documents. Critical data elements from documents are recognized and extracted by pre- trained ML/AI models through a rules-based engine. Incorrect, Out-of-date, Redundant, Incomplete, Incorrectly Formatted extracted data is cleansed utilizing DeepSight’s reverse lookup algorithm and pre- trained models. So, more insights and less effort. - Straight Through Processing (STP)
One of the key requisites for future-proofing any process is STP. Data from invoice documents is extracted, cleansed, transformed and invoices are created in Coupa without requiring any manual intervention or active monitoring is required. - Streamlined Exception Management
The system will be implemented with an exhaustive exception workflow to alert users for any manual input (if required). Real-time exceptions resolution mechanism available in the system (Review UI) aims to reduce redundant effort of filling same information every time with onset of new legal entities/funds/deals Our rule-based user interface ensures clean and consistent data, reducing errors, and streamlining the process for Coupa customers. - Enabling Traceability with Regimented and Well-defined Processes
One of the major requirements when it comes to invoice processing is traceability. DeepSight system provides audits in exception handling, error handling, and changes in rules. These are performed in a well-defined and regimented manner. All activities are documented as version changes or user actions as appropriate and can be accessed via the audit table or in the form of reports for further audit. - Create Standardized Nomenclature
All of the business rules/key parameters will be picked from a Single Golden Copy (maintained in DeepSight). This nullifies the chances of inadvertent human errors that can result in data integrity issues.
By embracing streamlined and automated invoice processing, it is possible for organizations to unlock multiple benefits. They can eliminate bottlenecks, improve accuracy, enhance visibility into financial operations, and achieve greater control over their accounts payable function. They are also in a better position to direct their time, effort and resources for more strategic and value-added tasks.
DeepSight futureproofs Invoice Processing for a Global Alternative Investment Manager
A global alternative investment manager that was facing problems due to its archaic largely manual- oriented invoice processing, was able to tackle high-level issues related to redundancy, productivity, costs, etc., with DeepSightTM. The customer’s business across different asset classes such as credit, private equity, and real estate, was difficult to manage due to the extremely high volumes of invoices. Manually mapping the complex business rules related to charges and tax withholdings was not an easy task to accomplish manually. With Magic FinServ’s DeepSightTM, the client was able to override the obstacles of time, operational costs, and errors while bolstering efficiency and productivity. Provided below is a step-by step guide of how DeepSight was able to meet the client’s objectives.
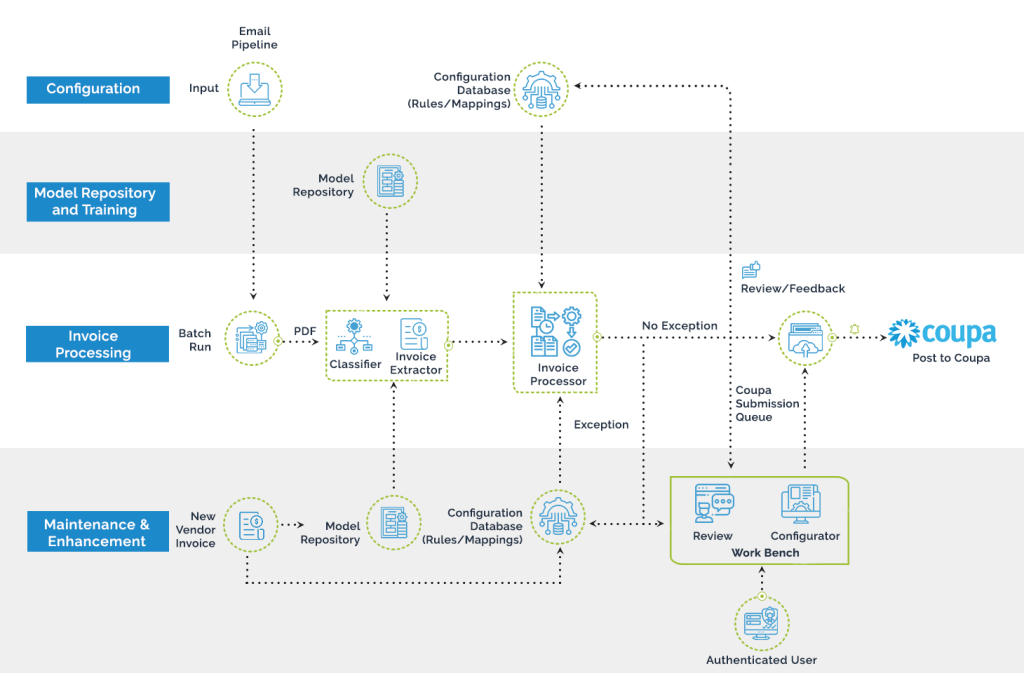
- Parse through diverse invoice formats whether it is an image, PDF, excel, etc., with ease
- Using DeepSight, the global alternative investment company, was able to extract information smartly and accurately related to different vendor invoices and carrying varied templates.
- One of the biggest advantages of the tool is its ability to self-learn user’s action and feedback, thereby making it easier for the tool to auto populate from new learnings.
- Our advanced and highly comprehensive solution based on AI/ML, fixated issues related to tax withholding and allocation with a rules-based approach.
- For ensuring seamless end-to end processing, data was enriched via RPA and an RPA-enabled workflow was implemented for approvals and authorizations processing.
- Using APIs for seamless integration with the core platform
The use case above exemplifies how DeepSightTM can be easily integrated with existing workflows or platforms to provide the results that firms had been looking for.
A truly transformative Invoice processing with DeepSightTM
While productivity and cost savings are the essential pillars of automated invoices, truly transformative invoice processing is one that focuses on increasing stakeholder satisfaction, improving agility and ensuring better management of working capital. For true transformation, additional value with quality and compliance, absolute traceability, and end-to-end control is also necessary. As a new shift is surfacing in the business ecosystem, it is time to redefine invoice processing and shift from the traditional approach to the DeepSightTM approach powered by AI technologies. With a highly refined and comprehensive solution that self learns with little help and has the gigantic capacity to scale up while ensuring end-to-end automated invoice processing of both PO and non-PO invoices, organizations not only can significantly reduce the percentage of errors and improve efficiency, but more essentially, they get a head start because of the deep insight they have gained thanks analytical capabilities of DeepSight (with rules-based approach) and an end-to-end solutioning of invoicing and prevention of revenue leakage.
For more information on how we can transform and enrich invoice processing with DeepSightTM, drop us a mail, at mail@magicfinserv.com to know about our invoice automation solutions. Even if you already have invested in an IP platform, you will be surprised to find what you are missing and how we can ensure a true end to end automation, where you will not have to worry about manual work ever again.