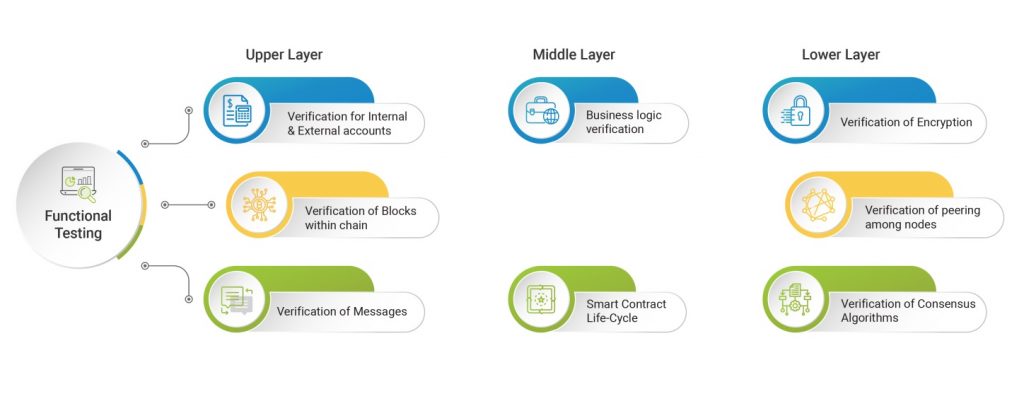
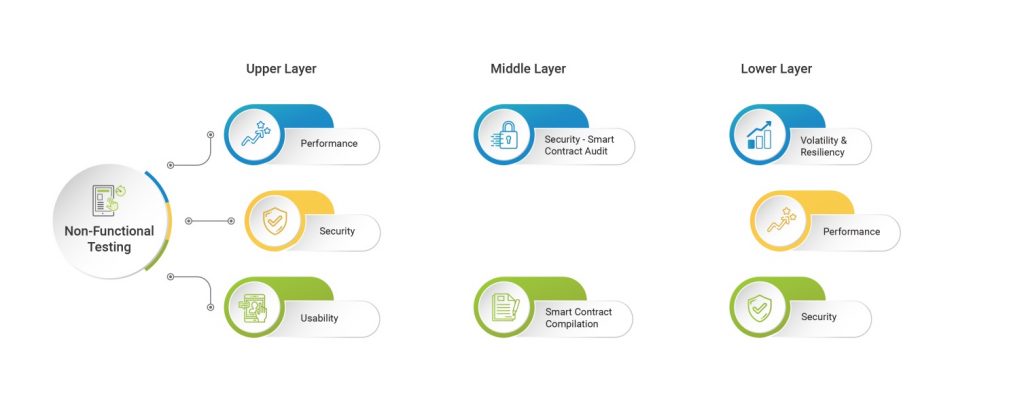
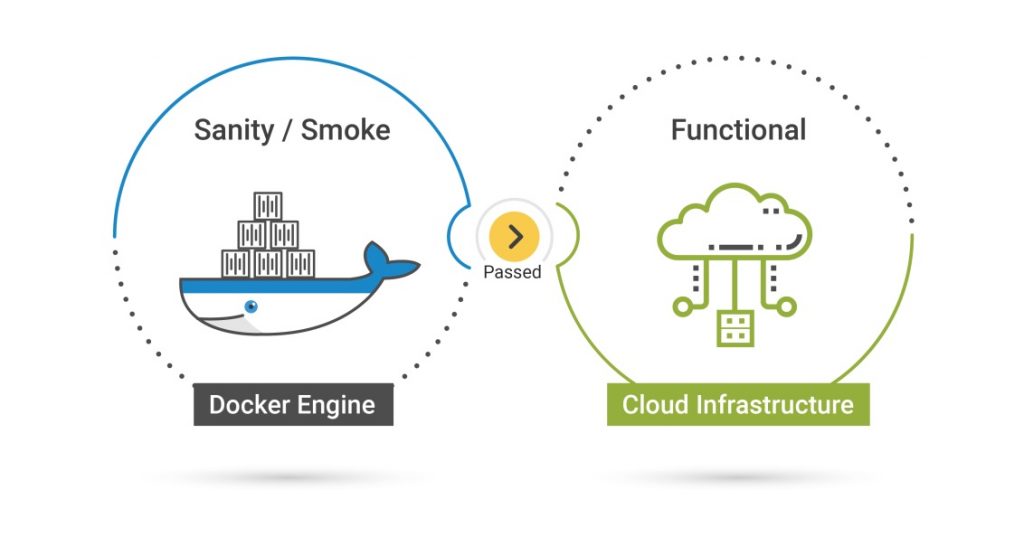
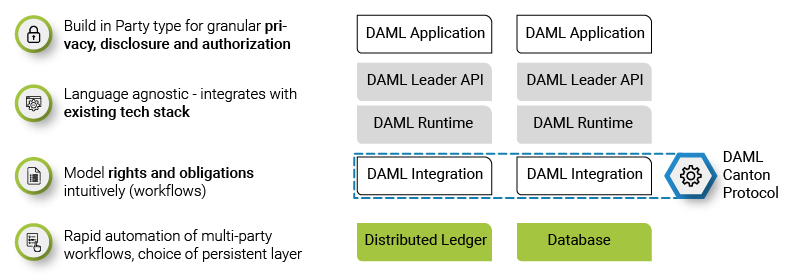
Enterprise-level distributed/decentralized applications have become an integral part of any organization today and are being designed and developed to be fault-tolerant to ensure availability and operability. However, despite the time and efforts invested in creating a fault-tolerant application, no one can be 100 % sure that the application will be able to bounce back with the nimbleness desired in the event of failures. As the nature of failure can differ each time, developers have to design, considering all kinds of anticipated failures/scenarios. From a broader perspective, the failures can any of the four types mentioned below:
- Failure Type1: Network Level Failures
- Failure Type2: Infrastructure (System or Hardware Level) Failures
- Failure Type3: Application Level Failure
- Failure Type4: Component Level Failures
Resiliency Testing – Defining the 3-step process:
Resiliency testing is critical for ensuring that applications perform as desired in real-life environments. Testing an application’s resiliency is also essential for ensuring quick recovery in the event of unforeseen challenges arising.
Here, the developer’s need is to develop a robust application that can rebound with agility for all probable failures. Due to the complex nature of the application, there are still unseen failures that keep coming up in production. Therefore, it has become paramount for testers to continually verify the developed logic to define the system’s resiliency for all such real-time failures.
Possible ways for testers to emulate real-time failures and check how resilient an application is against such failures
Resiliency testing is the methodology that helps to mimic/emulate various kinds of failures, as defined earlier. The developer/tester determines a generic process for each failure identified earlier before defining a strategy for resiliency testing for distributed and decentralized applications.
Based on our experience with multiple customer engagements for resiliency testing, the following 3-Step process must be followed before defining a resiliency strategy.
- Step-1: Identification of all components/services/any sort of third-party library or tool or utility.
- Step-2: Identification of intended functionality for each components/ services/ library/ tool/ utility.
- Step-3: Build an upstream and downstream interface and expected result to function and integration as per acceptance criteria.
As per the defined process, the tester has to collect all functional/non-functional requirements and acceptance criteria for all the four failure types mentioned earlier. Once all information gets collected, it should be mapped with the 3-step process to lay down what is to be verified for each component/service. After mapping for each failure using the 3-Step process, we are ready to define a testing strategy and automate the same to achieve accuracy while reducing execution time.
We elicited the four ways to define distributed/decentralized networks for the testing environment in our previous blog. This blog explains the advantages/disadvantages of each approach to set up applications in a test environment. It also describes why we prefer to first test such an application with containerized application followed by the cloud environment over virtual machines and then a physical device-based setup.
To know more about our Blockchain Testing solutions, read here.
Three modes of Resiliency testing
Each mode needs to be executed with controlled and uncontrolled wait times.
Mode1: Controlled execution for forcefully restarting components/services
Execution of “components restart” can be sequenced with a defined expected outcome. Generally, we flow successful and failed transactions followed by ensuring reflection of transactions on the system from overall system behavior. If possible, then we can assert the individual components/services response for the flowed transaction based on the intended functionality of restarted component/service. This kind of execution can be done with:
- The defined fixed wait time duration for restarting
- Randomly selecting the wait time interval.
Mode2: Uncontrolled execution (randomization for choosing component/service) for forcefully restarting components/services
Execution of a component restart can be selected randomly with a defined outcome. Generally, we flow successful and failed transactions, followed by ensuring reflection of the transaction on the system from overall system behavior. If possible, then we can assert the individual components/services response for the flowed transaction based on the intended functionality of restarted component/service. This kind of execution can be done with:
- The defined fixed wait time duration for restarting
- Randomly selecting a wait time interval.
Mode3: Uncontrolled execution (randomization for choosing multiple components/services) for forcefully restarting components/services
Though this kind of test is more realistic to be performed, it has a lot of complexity based on how the components/services are designed. If the number of components/services is too many, then the combination of test scenarios will increase exponentially. So the tester should create the test with the assistance of system/application architecture to make the group of components/services represent the entity within the system. Then Mode1 & Mode2 can be executed for those groups.
Types of Failures
Network Level Failures
As distributed/decentralized application uses peer-to-peer networking to establish a connection among the nodes, we need to get specific component/service detail on how it can be restarted. We also need to know how to verify the behavior during downtime and restarting the same. Let’s assume the system has one container within each node that is responsible for setting up communication with other available nodes; then the following verification can be performed –
- During downtime, other nodes are not able to communicate with the down node.
- No cascading effect of the down node occurs to the rest of the nodes within the network.
- After restart and initialization of restarted component/service, other nodes can establish communication with the down node, and the down node can also process the transaction.
- The down node can also interact with other nodes within the system and route the transaction as expected.
- Data consistency can be verified.
- Thestem’s latency can also be captured before/after the restart to ensure performance degradation is introduced to the system.
Infrastructure (System or Hardware Level) Failures
As the entire network is being run through containerized techniques so to emulate infrastructure failure, we can use multiple strategies like:
- By taking containerized application down or if Docker is being used, then taking docker daemon process down.
- By imposing a resource limit for memory, CPUs, etc., so low at the container level that it quickly gets exhausted with a mild load on the system.
- Overload the system with a high number of transactions with various sizes of data generated by the transaction.
We can verify if the system as a whole is meeting all functional and non-functional requirements with each failure described above.
Application Level Failure
As a distributed application uses a lot of containers to run the application, so we only target to stop and start a specific container having the application logic. The critical aspect for restarting application containers is the timing of stopping and starting the container to keep track of transaction processing. Three time-dependent stages for an application related to container stop and start are:
- Stage1: Stop the container before sending a transaction.
- Stage2: Stop the container after sending a transaction with different time intervals, e.g., stopping the container immediately, after 1000 milliseconds, 10 seconds, etc.
- Stage3: Stop the container when a transaction is in a processing stage.
System behavior can be captured and asserted against functional and non-functional acceptance criteria for all the above three stages.
Component Level Failures
The tester should verify the remaining containers for all three modes with three different stages with respect to time. We can create as many scenarios for these containers depending upon the following factors :
- The dependency of remaining containers on other critical containers.
- Intended functionality of the container and frequency of usage of those containers in most frequently used transactions.
- Stop and start for various time intervals (include all three stages to have more scenarios to target any fragile situation).
- Most fragile or unstable or mostly reported error within remaining containers.
By following the above-defined strategy for resiliency, the tester should always reconcile the application under test to check whether any areas are still left to be covered or not. If there is any component/service/third-party module or tool or utility that is untouched, then we can design scenarios by combining the following factors:
- Testing modes
- Time interval stages
- Execution mode, e.g., sequential and randomization of restarts
- Grouping of containers for stopping and restarting
Based on our defined approach followed by the implementation for multiple customers, we have prevented almost 60-70% of real-time issues related to resiliency. We also keep revising and upgrading our approach based on new experiences with new types of complicated distributed or decentralized applications and new failures so we can increase the prevention of real-time issues at a comprehensive level. To explore resiliency testing for your decentralized applications, please write to us at mail@magicfinserv.com.