
Automation in Loan Processing: Maximizing benefits and Improving Data Integrity Substantially!
"Noise in machine learning just means errors in the data, or random events that you cannot predict.”
"Noise" - the quantum of which has grown over the years in the loan processing, is one of the main reasons why bankers have been rooting for automation of loan processing for some time now. The other reason is data integrity, which gets compromised when low-end manual labor is employed during loan processing. In a poll conducted by Moody’s Analytics, when questioned about the challenges they faced in initiation of loan processing, 56% of the bankers surveyed answered that manual collection of data was the biggest problem.
Manual processing of loan documents involves:
- Routing documents/data to the right queue
- Categorizing/classifying the documents based on type of instruction
- Extracting information - relevant data points vary by classification and relevant business rules Feeding the extracted information into the ERP, BPM, RPA
- Checking for soundness of information
- Ensuring the highest level of security and transparency via an audit trial.
“There’s never time to do it right. There’s always time to do it over.”
With data no longer remaining consistent, aggregating, and consolidating dynamic data (from sources such as emails, web downloads, industry websites, etc.) has become a humongous task. Even when it comes to static data, the sources and formats have multiplied over the years, so manually extracting, classifying, tagging, cleaning, tagging, validating, and uploading the relevant data elements: currency, transaction type, counterparty, signatory, product type, total amount, transaction account, maturity date, the effective date, etc., is not a viable option anymore. And adding to the complexity is the lack of standardization in the Taxonomy with each lender and borrower using different terms for the same Data Element.
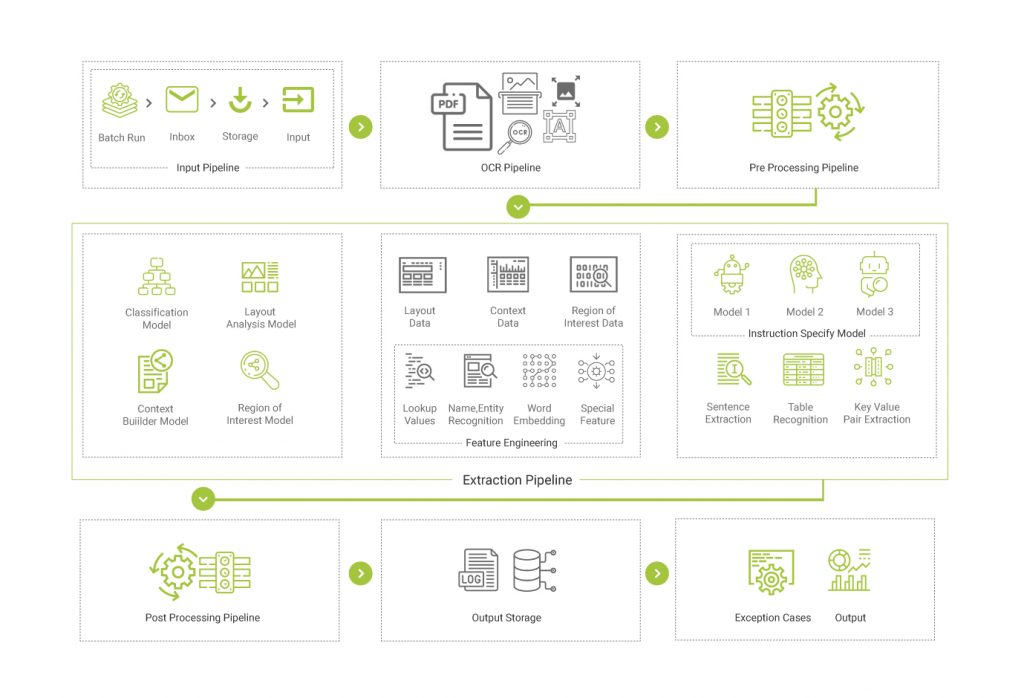
Hence, the need for automation, and integration of the multiple workflows used in loan origination - right from the input pipeline, the OCR pipeline, pre-and post-processing pipelines, to the output pipeline for dissemination of data downstream. With the added advantage of achieving a standard Taxonomy, at least in your shop.
The benefits of automating certain low-end, repetitive, and mundane data extraction activities
Reducing loan processing time from weeks to days: When the integrity of data is certain, when all data exchanges are consolidated and centralized in one place instead of existing in silos in back, middle, and front offices, only then can bankers reduce the loan processing time from months, weeks to days.
That was what JP Morgan Case achieved with COIN. They saved an estimated 360k hours or 15k days' worth of manual effort with their automated contract management platform. It is not hard to imagine the kind of impact it had on the customer experience (EX)!
More time for proper risk assessment: There is less time wasted in keying and rekeying data. With machines taking over from nontechnical staff, the AI (Artificial Intelligence) pipelines are not compromised with erroneous, duplicate data stored in sub-optimal systems. With administrative processes streamlined, there's time for high-end functions such as reconciliation of portfolio data, thorough risk assessment, etc.
Timely action is possible: Had banks relied on manual processes, it would have taken ages to validate the client, and by that time it could have been too late.
Ensuring compliance: By automating the process of data extraction from the scores of documents (that banks are inundated with during the course of loan processing) and by combining the multiple pipelines where data is extracted, transformed, cleaned, validated with a suitable business rules engines, and thereafter loaded for downstream, banks are also able to ensure robust governance and control for meeting regulatory and compliance needs.
Enhances the CX: Automation has a positive impact on CX. Bankers also save dollars in compensation, equipment, staff, and sundry production expenses.
Doing it Right!
One of Magic FinServ's success stories comprises a solution for banking and financial services companies that successfully allows them to optimize the extraction of critical data elements (CDE) from emails and attachments with Magic's bespoke tool – DeepSightTM for Transaction processing and accelerator services.
The problem:
Banks in the syndicated lending business receive large volume of emails and other documented inputs for processing daily. The key data is embedded in the email message or in the attachment. The documents are in PDF, TIF, DOCX, MSG, XLS, form. Typically, the client's team would manually go through each email or attachment containing different Loan Instructions. Thereafter the critical elements are entered into a spreadsheet and then, uploaded, and saved in the bank's commercial loan system.
As is inherent here there are multiple pipelines for input, pre-processing, extraction, and finally output of data, which leads to duplication of effort, is time consuming, resulting in false alerts, etc.
What does Magic Solution do to optimize processing time, effort, and spend?
- Input Pipeline: Integrate directly with an email box or a secured folder location and execute processing in batches.
- OCR Pipeline: Images or Image based documents are first corrected and enhanced (OCR Pre-Processing) before feeding them to an OCR system. This is done to get the best output from an OCR system. DeepSightTM can integrate with any commercial or publicly available OCRs.
- Data Pre-Processing Pipeline: Pre-Processing involves data massaging using several different techniques like cleaning, sentence tokenization, lemmatization etc., to feed the data as required by optimally selected AI models.
- Extraction Pipeline: DeepSight’s accelerator units accurately recognize the layout, region of interest and context to auto-classify the documents and extract the information embedded in tables, sentences, or key value pairs.
- Post-Processing Pipeline: Post-Processing pipeline applies all the reverse lookup mappings, business rules etc. to further fine tune accuracy.
- Output Storage: Any third-party or in-house downstream or data warehouse system can be integrated to enable straight through processing.
- Output: Output format can be provided according to specific needs. DeepSightTM provides data in excel, delimited, PDF, JSON, or any other commonly used format. Data can also be made available through APIs. Any exception or notifications can be routed through emails as well.
Technologies in use
Natural language processing (NLP): for carrying out context-specific search from emails and attachments in varied formats and extracts relevant data from it.
Traditional OCR: for recognizing key characters (text) scattered anywhere in the unstructured document is made much smarter by overlaying an AI capability.
Intelligent RPA: is used to consolidate data from various other sources such as ledgers, to enrich the data extracted from the documents. And finally, all this is brought together by a Rules Engine that captures the organization's policies and processes. With Machine Learning (ML) and a human-in-the-loop approach to carry out truth monitoring, the tool becomes more proficient and accurate every passing day.
Multi-level Hierarchy: This is critical for eliminating false positives and negatives since payment instructions could comprise of varying CDEs. The benefits that the customer gets are:
- Improve precision on Critical Data Elements (CDEs) such as Amounts, Rates and Dates etc.
- Contains false positives and negatives to reduce the manual intervention
Taxonomy: Train the AI engine on taxonomy is important because:
- Improve precision and context specific data extraction and classification mechanism
- Accuracy of the data elements which refer to multiple CDEs will improve. For e.g., Transaction Type, Dates and Amounts
Human-eye parser: For documents that contain multiple pages and lengthy preambles you require a delimitation of tabular vs. free flow text. The benefits are as follows:
- Extraction of tabular data, formulas, instructions with multiple transaction types all require this component for seamless pre and post processing
Validation & Normalization: For reducing the manual intervention for the exception queue:
- An extensive business rule engine that leverages existing data will significantly reduce manual effort and create an effective feedback loop for continuous learning
OCR Assembling: Highly required for image processing of vintage contracts and low image quality (i.e., vintage ISDAs):
- Optimize time, cost and effort with the correct OCR solution that delivers maximum accuracy.
Conclusion
Spurred on by competition from FinTech and challenger banks, that are using APIs, AI, and ML for maximizing efficiency of loan processing, the onus is on banks to maximize efficiency. The first step is ensuring data integrity with the use of intelligent tools and business-rules engines that make it easier to validate data. It is after all much easier to pursue innovation and ensure that SLAs are met when workflows are automated, cohesive, and less dependent on human intervention. So, if you wish to get started and would like more information on how we can help, write to us mail@magicfinserv.com.

