
Tackling data consolidation & aggregation challenges the Magic FinServ way
The Buy-Side and Investment Managers thrive on data – amongst the financial services players, they are probably the ones that are the most data-intensive. However, while some have reaped the benefits of a well-designed and structured data strategy, most firms struggle to get the intended benefits primarily because of the challenges in consolidation and aggregation of data. In their defense however, Data Consolidation and Aggregation challenges are more due to gaps in their data strategy and architecture.
Financial firms' core Operational and Transactional processes and the follow-on Middle Office, Back Office activities such as reconciliation, settlements, regulatory compliance, transaction monitoring and more depend on high-quality data. However, if data aggregation and consolidation are less than adequate, the results are skewed. As a result, investment managers, wealth managers, and service providers are unable to generate accurate and reliable insights/information on Holdings, Positions, Securities, transactions, etc., which is bad for trade and shakes the investor's confidence. Recent reports of a leading Custodian’s errors in account set up due to faulty data resulting in less than eligible Margin Trading Limits are classic examples of this problem.
In our experience of working with many buy-side firms and financial institutions, the data consolidation and aggregation challenges are largely due to:
Exponential increase in data in the last couple of years: Data from online and offline sources must both be aggregated and consolidated before being fed into the downstream pipeline in a standard format for further processing.
Online data primarily comes from these three sources:
- Market and Reference Data providers
- Exchanges which are the source of streaming data
- Transaction data from inhouse Order Management Systems or from the prime brokers and custodians, often this is available in different file formats, types, and taxonomies thereby compounding the problem.
Offline data comes also through emails for clarifications, reconciliation of the data source in email bodies, attachments as PDF’s, web downloads etc., which too must be extracted, consolidated, and aggregated before being fed into the downstream pipeline.
Consolidating multiple taxonomies and file types of data into one: The data that is generated either offline or online comes in multiple taxonomies and file types all of which must be consolidated in one single format before being fed into the downstream pipeline. Several trade organizations have invested heavily to create Common Domain Models for a standard Taxonomy; however, this is not available across the entire breadth of asset and transaction types.
Lack of real-time information and analytics: Investors today demand real-time information and analytics, but due to the increasing complexity of the business landscape and an exponential increase in the volume of data it is difficult to keep abreast with the rising expectations. From onboarding and integrating content to ensuring that investor and regulatory requirements are met, many firms may be running out of time unless they revise their data management strategy.
Existing engines or architecture are not designed for effective data consolidation: Data is seen as critical for survival in a dynamic and competitive market – and firms need to get it right. However, most of the home-grown solutions or engines are not designed for effective consolidation and aggregation of data into the downstream pipeline leading to delays and lack of critical business intelligence.
Magic FinServ's focused solution for data consolidation and integration
Not anymore! Magic FinServ's Buy-Side and Capital Markets focused solutions leveraging new-age technology like AI (Artificial Intelligence), ML (Machine Learning), and the Cloud enable you to Consolidate and Aggregate your data from several disparate sources, enrich your data fabric from Static Data Repositories, and thereby provide the base for real-time analytics. Our all-pervasive solution begins with the understanding of where your processes are deficient and what is required for true digital transformation.
It begins with an understanding of where you are lacking as far as data consolidation and aggregation is concerned. Magic FinServ is EDMC’s DCAM Authorized Partner (DAP). This industry standard framework for Data Management (DCAM), curated and evolved from the synthesis of research and analysis of Data Practitioners across the industry, provides an industrialized process of analyzing and assessing your Data Architecture and overall Data Management Program. Once the assessment is done, specific remediation steps, coupled with leveraging the right technology components help resolve the problem.
Some of the typical constraints or data impediments that prevent financial firms from drawing business intelligence for transaction monitoring, regulatory compliance, reconciliation in real-time are as follows:
Data Acquisition / Extraction
- Constraints in extracting heavy datasets, availability of good API’s
- Suboptimal solutions like dynamic scrapping in case API are not easily accessible
- Delay in source data delivery from vendor/client
- Receiving revised data sets and resolving data discrepancies across different versions
- Formatting variations across source files like missing/ additional rows and columns
- Missing important fields / Corrupt data
- Filename changes
Data Transformation
- Absence of a standard Taxonomy
- Creating a unique identifier for securities amongst multiple identifiers (Cusip, ISIN etc.)
- Data arbitrage issues due to multiple data sources
- Agility of Data Output for upstream and downstream system variations
Data Distribution/Loading
- File formatting discrepancies with the downstream systems
- Data Reconciliation issues between different systems
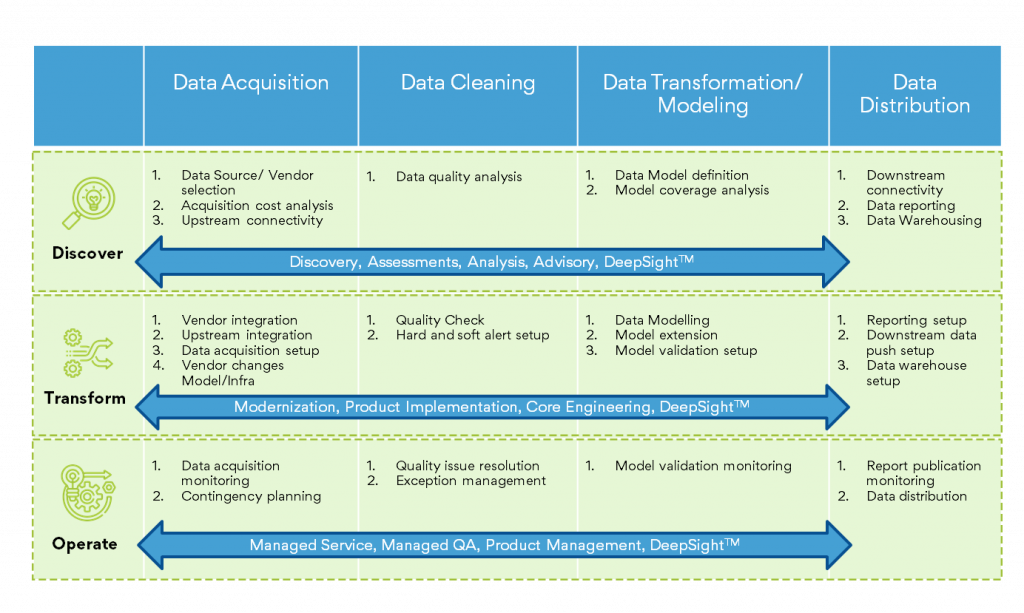
How we do it?
Client Success Stories: Why to partner with Magic FinServ
Case Study 1: For one of our clients, we optimized data processing timelines & reduced time and effort by 50% by optimizing the number of manual overrides for identifying an asset type of new securities by analyzing the data, identifying the patterns, extracting the security issuer, and conceptualizing a rule- based logic to generate the required data. Consequently, manual intervention was required only for 5% of the records manually updated earlier in the first iteration itself.
In another instance, we enabled the transition from manual data extraction from multiple worksheets to more streamlined and efficient data extraction. We created a macro that selects multiple file source files and uploads data in one go – saving time, resources, and dollars. The macro fetched complete data in the source files even when the source files had some filters applied to the data (accidentally). The tool was scalable, so it could be easily used for similar process optimization instances. Overall, this tool enabled reduced data extraction efforts by 30-40%.
Case Study 2: We have worked extensively in optimizing reference data. For one prominent client, we helped onboard the latest Bloomberg industry classification, and updated data acquisition and model rules. We also worked with downstream teams to accommodate the changes.
The complete process of setting up a new security - from data acquisition to distribution to downstream systems, took around 90 minutes (about 1 and a half hours) and users needed to wait till then for trading the security. We conceptualized and created a new workflow for creating a skeleton security (security with mandatory fields) which can be pushed to downstream system in 15 minutes. If sec is created in skeleton mode, only the mandatory data sets/tables were updated and subsequently processed. Identification of such DB tables was the main challenge as no documentation was available.
Not just the above, we have worked with financial firms extensively and ensured that they are up to date with the latest - whether it be regulatory data processing, or extraction of data from multiple exchanges, or investment monitoring platform data on-boarding, or crypto market data processing. So,
if you want to know more, visit our website, or write to us at mail@magicfinserv.com.

